NOSQL
- NOSQL 특징
- Not only SQL의 약자로 기존의 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미한다.
- RDBMS: 테이블 형태의 공통된 저장방식
- NoSQL: 데이터 간의 스키마, 관계를 정의하지 않는다.
- 분산형 구조를 통해 데이터를 여러 대의 서버에 분산 저장, 분산 시에 데이터를 상호 복제해 특정 서버에 장애가 발생했을 때에도 데이터 유실이나 서비스 중지가 없는 형태
- 분산형 구조를 띄고 있기 때문에 CAP 이론을 띄고 있다.
- Not only SQL의 약자로 기존의 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미한다.
- CAP 이론: 분산 컴퓨팅 환경은 Consistency, Availability, Partitioning 3가지 특징을 가지고 있으며, 이중 2가지만 만족한다는 이론
- 일관성(Consistency)
- 모든 노드들은 같은 시간에 동일한 항목에 대하여 같은 내용의 데이터를 사용자에게 보여준다.
- 가용성(Availability)
- 모든 사용자들이 읽기 및 쓰기가 가능해야 하며, 몇몇 노드의 장애 시에도 다른 노드에 영향을 미치면 안된다.
- 클러스터 내에 몇 개 노드가 고장나도 정상적인 서비스를 제공해야 한다
- 마스터 슬레이브 복제, 피어 투 피어 복제 등에 방법을 통해 제겅한다
- 분할내성(Partition tolerance)
- 메시지 전달이 실패하거나 시스템 일부가 망가져도 시스템이 계속 동작할 수 있어야 한다.
- 지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서 네트워크 단절, 네트워크 데이터 유실이 일어나더라도 각 지역 내의 시스템은 정상적으로 동작해야 됨을 의미한다
- CP Category: There is a risk of some data becoming unavailable (MongoDB, HBase, Memcache, BigTable, Redis)
- CA Category: Network problem migigt stop the system (RDBMS)
- AP Category: Clients may read inconsistent data (Cassandra, RIAK, CouchDB)
- 일관성(Consistency)
- NOSQL 장단점
- 특정 용도로 특화되어 있기 때문에 솔루션의 특징을 알 필요가 있다.
- 데이터 분산에 용이하고 Join 연산은 대부분 불가능하다. 즉, 데이터 모델 자체가 독립적으로 설계되어 있어 데이터를 여러 서버에 분산시키는 것이 용이함
- 데이터에 대한 캐시가 필요하거나 배열 형식의 데이터를 고속으로 처리할 필요가 있는 경우에 사용
- NOSQL 종류
- Key/Value Store
- 대부분의 NOSQL은 Key/Value 개념을 지원하며 Unique한 Key에 하나의 Value를 가지고 있는 형태
- put(key, value), value := get(key) 형태 API 사용 (ex, redis)
- Ordered Key/Value Store
- Key 기준으로 sorting이 되어 있고 Key 안에 column:value 조합으로 된 여러개의 필드를 가지는 구조
- Hbase, cassandra
- Document Key/Value Store
- Key Value Store 의 확장된 형태
- 저장되는 Value 의 데이터 타입으로 “Document”라는 구조화된 데이터 타입(JSON, XML, YAML 등)을 사용
- 복잡한 계층 구조 표현 가능
- 제품에 따라 추가 기능(Sorting, Join, Gouping) 지원
- Key/Value Store
NOSQL 데이터 모델링
- 특징 1. Denormalization(비정규화)
- 쿼리 프로세싱 최적화, 특정 데이터 모델에 맞추기 위해서 같은 데이터를 여러 도큐먼트나 테이블에 복제하여 중복하는 것을 허용
- 비정규화로 인해 쿼리 수행 복잡도는 낮아지지만, 전체 데이터 사이즈는 커지지만 분산환경, 대용량 데이터 처리에 적합하다.
- 특징 2. Aggregates
- 유연한 스키마 속성은 복잡하고 다양한 구조의 내부 요소(nested entities) 를 가지고 있는 데이터 클래스를 구성 가능하게 한다.
- 1:N 관계를 최소화하여 결과적으로 Join 연산을 줄인다. (수행시간 단축)
- 복잡하고 다양한 비즈니스 요소를 담을 수 있다. (추후 확장성 및 변동성에 대한 유연한 대응 가능)
- linked vs embedding
- linked
- 특징: 더 복잡하지만 유연한 데이터 구조, 상대적으로 강한 일관성 제공 가능
- File: id, size, data, name, directory, subId
- MP3 extends File: musicId, title, artist
- Photo extends File: photoID, format
- Movie extends File: movieID, format, title, length
- embedding
- 특징: 빈번한 업데이트, 크기가 증가하는 업데이트일 때는 권장하지 않음, 한번의 쿼리로 조회하기 때문에 읽기 속도 향상
- File: { type: “mp3”, 공통필드(fileID, size, data, name, directory), meta: { title: “music title”, artist: “singer”, format: “”, length: “” }
- linked
- 특징3. Application Side Joins
- Deserialization, Aggregation을 통해 Join 을 사용하지 않게 설계하지만 정규화가 필요한 경우가 있다.
- 업데이트가 빈번하게 이뤄지는 경우, 중복된 데이터를 모두 업데이트 해야 되는 경우
- Join 대상 데이터가 다대다 관계인 경우
- 해당에 경우 Application 에서 join을 만들어준다.
V1 = Get(key) from collection1 V2 = Get(collection1.key) from collection2 return {V1, V2};
- Deserialization, Aggregation을 통해 Join 을 사용하지 않게 설계하지만 정규화가 필요한 경우가 있다.
- 계층 데이터 구조 모델링 패턴 (Tree 구조에 대한 모델링)
- NOSQL은 다양한 데이터 모델이 있지만, 기본적으로 row, column을 가지고 있는 테이블 구조의 저장 구조를 갖지만 Tree와 같은 계층형 데이터 구조를 저장해야 할 경우 NOSQL은 이런 계층형 구조를 저장하는 것이 쉽지 않음
- RDBMS의 경우에도 이런 계층형 구조를 저장하기 위해서 많은 고민을 해왔기 떄문에, 솔루션에서 기능적으로 자체 지원하기도 하고 데이터 모델링을 통해서 계층형 구조를 저장할 수 있음
-
NoSQL에서 계층형 구조를 저장하는 기법은 RDBMS에서 사용하는 기법들을 참고하여 구현함
- 방법 1. Tree Aggregation
- Tree 구조 자체를 하나의 Value에 JSON, XML등을 활용(nested)하여 저장하는 방식
- Tree 자체가 크지 않고, 변경이 많이 없는 경우에 적합
-
방법2. Materialized Path
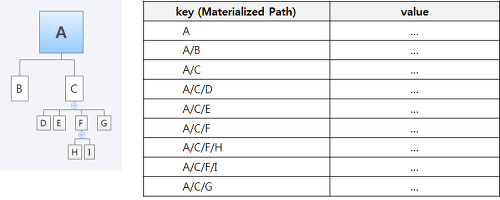
- Tree 구조를 테이블에 저장할 때, root에서부터 현재 노드까지의 전체 경로를 key로 저장하는 방법
- Key를 Search 할 때 Regular Expression 사용하여 특정 노드의 하위 트리 쿼리해 오는 기능 등 다양한 쿼리 가능
- 관계
- RDBMS vs NO SQL
- 관계형 DB는 ERD를 통해 관계를 선정하고 사용 패턴에 대해 Join하여 데이터를 보여준다
- NO SQL은 사용패턴에 대한 정의(Access Pattern)를 한 후 모델링 방법을 정의한다
- Referencing
- MongoDB에서는 Referencing 2가지를 제공한다
- 수동참조: 다큐먼트에 foreign key를 필드로 생성하여 진행
- DBRef: 특정 참조 유형을 나타내는 것이 아닌 문서 자체를 나타내는 규칙
- 장점: 작은 다큐먼트 유지, 16MB 다큐먼트 사이즈 제한에서 자유, 데이터 중복이 없음
- 단점: 두 개의 쿼리(or $lookup) 필요, 관련된 정보를 원자성을 가지고 동시에 업데이트 불가(트랜잭션이 있다면 가능)
- MongoDB에서는 Referencing 2가지를 제공한다
- Embedding
- 필요한 결과를 모두 갖고 있는 형태
- 장점: 단일 질의/문서 에서 모든 관련 정보를 검색 가능하며 단일 원자성 작업으로 관련 정보 업데이트가 가능하다
- 단점: 데이터 중복 가능성이 있으며, 연관성이 없을 경우 큰 다큐먼트는 오버헤드(16MB document size limit) 발생
- RDBMS vs NO SQL
- Design Pattern
- Attribute Pattern(Big Documents, Many Fields, Many Indexes)
- 문제점: 유사한 필드가 많고 해당 필드를 함께 검색하는 특성, 다큐먼트의 작은 subset 형태로만 존재
- 해결방안: Array 형태로 필드를 묶음, 필드와 값을 서브 다큐먼트 형태로 분리
- 예시
- 만약 영화 제목에 대한 나라별 개봉일을 저장하는 컬렉션이 있다면, 나라별 개볼일을 개별 필드로 생성하면 인덱스가 너무 많이 필요하게 된다
- 이럴 때는 릴리스 필드를 하나 두고, array 형태로 변경할 수 있다.
- Extended Reference Pattern
- 문제점: 일부 데이터가 계속 필요하여 반복적인 조인이 발생
- 해결방안: Lookup 하는 컬렉션 쪽에서 필드를 정의, 해당 필드를 메인 오브젝트로 가져옴
- Subset Pattern
- 문제점: Array를 두어 데이터 중첩을 할 때 다큐먼트의 크기가 너무 커지는 경우
- 해결방안: 컬렉션을 두개로 분리(많이 사용되는 필드에 대한 다큐먼트와 적게 사용되는 필드에 대한 다큐먼트)
- Bucket Pattern
- 문제점: 너무 많은 문서나 하나의 사이즈가 너무 큰 문서, Embedded 시킬 수 없는 1:N 관계
- 해결방안: 함께 그룹화할 최적의 정보량 정의, 주 객체에 정보를 저장하는 Array 생성
- Computed Pattern
- 문제점: 비용이 많이 드는 데이터의 계산 또는 데이터 조작, 동일 데이터에서 빈번히 실행되고 동일한 결과를 생성하는 경우
- 해결방안: 작업을 수행하고 결과를 별도의 문서나 컬렉션에 저장, 작업을 다시 실행해야 하는 경우를 대비하여 소스 유지
- Schema Versioning Pattern
- 문제점: 스키마 업그레이드를 수행하는 동안 다운 타임 방지, 대량의 데이터를 다루는 경우에 있어 모든 문서를 업그레이드하는 건 시간이 오래 걸릴 수 있음, 모든 문서를 업데이트하고 싶지 않은 경우
- 해결방안: 각 다큐먼트가 schema_version 필드를 가짐, Application이 모든 버전을 관리, 기존 다큐먼트를 새 버전으로 변경
- Attribute Pattern(Big Documents, Many Fields, Many Indexes)
- 데이터 모델링 예시
- 순서 1. 도메인 모델 파악
- 어떤 데이터 개체가 있는지, 개체간의 관계 분석
- 저장할 데이터를 명확하게 이해하기 위해 필요(RDBMS와 동일)
- 순서 2. 쿼리 결과(데이터 출력 형태) 디자인
- 도메인 모델 기반으로 어플리케이션에서 쿼리가 수행되는 결과값을 먼저 정함
- 출력 형식을 기반으로 필요한 쿼리 정의
- 출력 데이터를 기반으로 테이블 추출
- RDBMS와는 정반대의 순서를 가지고 있다.
- 순서 3. 패턴을 이용한 데이터 모델링
- NoSQL은 Sorting, Grouping, Join 등의 연산을 제공하지 않기 때문에 Get/Put으로만 데이터를 처리할 수 있는 형태로 데이터 모델 재정의
-
예시
Table Key Value Category userId:categoryID categoryName(value) Posting userID:postID categoryName(value), title(value), date(value), contents(value) Attachment userID:postID:fileID filename(value), date(value), location(value) comment userID:postID:commentID commentUser(value), date(value), comment(value)
-
순서 3. 기능 최적화
- 순서 4. NoSQL 선정 및 테스트
- 모델링한 데이터 구조를 효과적으로 실행할 수 있는 NoSQL 검토, NoSQL 특성 분석 및 부하테스트, 안정성/확장성 테스트 수행
- 순서 5. 선정된 NoSQL에 최적화된 하드웨어 디자인까지 해야 한다.
- 순서 1. 도메인 모델 파악
MongoDB
- MongoDB 특징
- 메모리맵 형태의 파일 엔진 DB이기 때문에 메모리에 의존적
- 메모리 크기가 성능을 좌우
- 쌓아놓고 삭제가 없는 경우 적합
- 로그 데이터, 이벤트 참여 내역, 세션
- 트랜잭션이 필요한 금융, 결제 등에는 부적합하기 때문에 RDBMS와 혼용
- JSON형태의 도큐먼트 데이터 모델(데이터 설계를 종이문서 설계하듯이 설계해야 한다)
- 몽고DB 내부에서는 BSON(Binary) 형태로 저장하고 주고받게 되어 있다
{ "id": 1, "title": "Welcome to Mongo DB", "body": "Today, we...", "published": true, "created": "2021-10-10 13:00", "updated": "2021-10-10 13:00", "tags": ["databases", "MongoDB", "awesome"], "comments": [ { comment_id: 2, "author": "Bob", "email": "bob@test.com", "body": "Good!", "created": "2021-10-10 13:05" } ] }
- 메모리맵 형태의 파일 엔진 DB이기 때문에 메모리에 의존적
- 장점
- Schema-less 구조
- Read/Write 성능 뛰어남
- 쓰기: 100배, 읽기: 3배 정도 빠르다.
- Scale out 구조
- 단점
- 데이터 업데이트 중 장애 발생 시, 데이터 손실 가능
- 많은 인덱스 사용 시, 충분한 메모리 확보 필요
- 데이터 공간 소모가 RDBMS에 비해 많음 (비효율적인 Key 중복 입력)
- 복잡한 JOIN 사용 시 성능 제약이 따름
- Transactions 지원이 RDBMS 대비 미약함
- 제공되는 MapReduce 작업이 Hadoop에 비해 성능이 떨어짐
- 빅데이터 처리 특화
- Memory Mapped(데이터 쓰기 시에 OS의 가상 메모리에 데이터를 넣은 후 비동기로 디스크에 기록하는 방식)을 사용
- 방대한 데이터 빠르게 처리 가능
- OS의 메모리를 활용하기 때문에 메모리가 차면 하드디스크로 데이터 처리하여 속도가 급격히 느려짐
- 하드웨어적인 측면에서 투자 필요
- MongoDB 불안전성
- 데이터 양이 많을 경우 중간 중간 일부 데이터를 유실할 수 있다
- 샤딩의 비정상적인 동작 가능성
- 레플리카 프로세스의 비정상 동작 가능성
- 데이터 양이 많을 경우 중간 중간 일부 데이터를 유실할 수 있다
출처
- CAP 이론: https://itwiki.kr/w/CAP_%EC%9D%B4%EB%A1%A0
- T아카데미 유투브 강의, MongoDB 프로그래밍: https://www.youtube.com/playlist?list=PL9mhQYIlKEheyXIEL8RQts4zV_uMwdWFj